Recently I came across a bit of an interesting problem.
An application I was working with had functionality that required the generation of user-friendly identifiers (e.g. 8 or less numbers). This seemed to be working pretty well the first day we looked at it: each new user was getting an incremental ID and things were smooth.
![]()
The second day there was a reasonable gap overnight in the ID range and as far as I could tell the bank account wasn’t overflowing with new business, so that was a bit odd. Still, I let it go as it didn’t seem to be doing any major harm yet.

Third day there was a gap overnight again, and this time it had wrapped around and started generating lower identifiers!

While not a major issue in terms of sequencing or overflow (we just needed unique IDs), I was immediately concerned about whether the identifiers were really unique: why were we getting nightly “jumps” and how quick until we got unlucky enough to start overlapping?
It was time to look under the hood.
MongoDB ObjectIds and UUIDs
The application was using MongoDB for storage. Though I’d come across the NoSQL concept since around 2009 through the usual channels, I was admittedly fairly late to putting it into much practice. So it came as a bit of a surprise that MongoDB did not have out-of-the-box functionality to generate incremental identity values, but instead relies on a bit of scripting to achieve a similar approach.
Of course pausing for a moment and thinking about high-performance distributed environments I realised it made some sense to have an independent process to reliably generate unique identifiers (e.g. UUID Generation) that did not depend on insert locking and allowed nodes to act independently.
In fact, the MongoDB BSON ObjectId values look and feel pretty much like a custom UUID along the lines of RFC 4122.
Contrast UUIDs/GUIDs:
- 60 bits of timestamp
- 48 bits of computer identifier
- 14 bits of uniquifier
- 6 bits are fixed
- 128 bits total (16 bytes)
With the BSON ObjectId
- 32 bits representing the seconds since the Unix epoch
- 24 bits of machine identifier
- 16 bits of process id
- 24 bits for an increment counter, starting with a random value
- 96 bits total (12 bytes)
Importantly, as with GUID’s a substring of the full identifier is not unique. This is pretty natural when you consider that your substring might just be the timestamp (and two PCs could have the same timestamp, you might generate two IDs at the same time, clocks can change, leap seconds etc.).
The MongoDB Increment Counter
With this in mind, returning to my recent MongoDB experience I noticed that while the standard full BSON ObjectId values were being used for object identifiers (good), it was clear that the user identifiers were being generated elsewhere to ensure they had something more user-friendly than 24 alphanumeric characters.
To this end someone had decided to use the increment counter value of the BSON ObjectId, which made some sense given the description of “a counter, starting with a random value”.
Indeed this incremental behaviour is what you would see during a test run, with wrapping should the counter be exceeded (say due to a high initial random value). Furthermore, at 3 bytes the value was effectively an unsigned mediumint as well, which meant a maximum of 16777215 or 8 digits or less for users to recite, and plenty of space for our expected number of lifetime identifiers. Perfect right?
Clearly something wasn’t lining up, so I dove in with Reflector and had a look at the MongoDB driver code, specifically GenerateNewId in MongoDB.Bson.ObjectId.
As described, at first glance it was a counter just incrementing away:
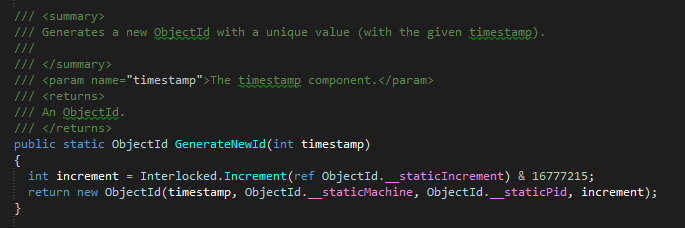
But incrementing what?
![]()
Ah, a static variable initialised with new Random().Next() – that would explain it. Each time the application was starting, or restarting, which was at least every 29 hours, this variable was being reset with a chance each time of landing on or near to a previously generated “increment value”. What’s more, if we had multiple application domains in the production environment we would have an even greater risk of overlapping.
Now of course for the purposes of an ObjectId the random seed is just one part of the puzzle so it presents fairly minimal issues unless there are more than 1677715 (2^24) ObjectId’s generated in the same second. The minimal risk of multiple AppDomains on the same machine generating the same increment counter within the same second is addressed by the inclusion of the Application Domain ID as part of the machine identifier component of the ObjectId. However, by taking just the increment counter in isolation we didn’t have these safeguards.
Then again, there were still nearly 17 million possible counter spots: surely intuition would say the chances of getting the same counter again on an AppDomain restart was pretty low…
The Birthday Problem
So interesting trivia:
What are the chances of two people in an average small office (say 23 people) having the same birthday?
Something like 23/365? Maybe a bit lower or a bit higher?
What about a larger office of say 70 people?
Turns out (and you’ve probably heard this one before) that the small office has a 50% chance of two people sharing the same birthday, and the larger office has a 99.9% chance. Why does this matter? Well it turns out our counter regeneration was just an example of the Birthday Problem, albeit with less funny hats than we’d usually hope for, and a disappointing absence of cake.
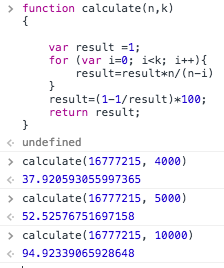
Running the numbers (via a convenient bit of JS ran through Chrome Dev Tools), it turned out after 4000 AppDomain restarts there was a 37% chance of overlapping, this was 52% by 5000 restarts, and 94.9% by 10000 restarts. While that might buy us a few months or even years, I didn’t want to be rolling the dice on uniqueness.
Just to be sure, I decided I’d also write up a quick simulator of the experience, factoring for the number of AppDomain restarts and the average number of generated identifiers each AppDomain. It became clear that there were some trade-offs depending on the generation rate vs the AppDomain restart rate, but the general principle held.
Indeed from just a couple of quick anecdotal runs (I’m sure it could be run and graphed properly):
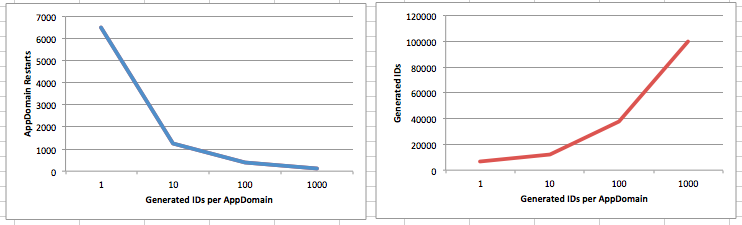
- 1 ID generation per AppDomain restart meant between 3,000 and 10,000 AppDomain restarts before a collision (equating to about as many days).
- 10 ID generations per AppDomain restart meant between 750 and 1,500 AppDomain restarts (meaning less days) before a collision, but between 7,500 and 15,000 generated IDs (an increased number of IDs).
- 100 ID generations per AppDomain restart meant only 250 to 500 AppDomain restarts but 25,000 to 50,000 generated IDs.
- 1000 ID generations per AppDomain restart meant 100 to 150 AppDomain restarts and 50,000 to 150,000 generated IDs.
While some of these rates were low enough that you could potentially last a couple of years, others were not, and it was ultimately a dangerous and unnecessary game of luck to be playing when there were good incremental alternatives.
Ultimately it meant we should either:
- Change the generation method to have a concept of already generated identifiers
- Or, change the generation method to be unique without randomness or high collision risk (quite a challenge to keep short)
- Or, accept the non-unique IDs, and request supporting info (e.g. as airlines do) when using the identifier.
However, the overall takeaway was: Don’t use the MongoDB Increment value as a Unique Identifier.
For reference here is the simulation code I whipped up and ran in LINQPad
void Main()
{
List<int> generatedIds = new List<int>();
var r = new Random();
for (int restart=0; restart<100000; restart++)
{
int __staticIncrement = r.Next();
for (int generated=0; generated<1000; generated++)
{
int generatedId = __staticIncrement++ & 16777215;
generatedIds.Add(generatedId);
if (generatedIds.Count(d => d == generatedId) > 1)
{
//generatedId.Dump();
(restart + " " + generated).Dump();
}
}
}
}








{kind=link}