Had the interesting problem today of trying to detect duplicate XML values in a SQL Server table (stored in a column of field type XML).
I’m not the first to cover this issue:
- Matt Woodward has covered the simplest case of duplicate checks
- There’s a StackOverflow question covering it
However, my “requirements” as they were differed a little from the existing solutions:
- Only compare a subset of the XML value (a timestamp header would still differ on XML values we considered duplicates)
- Only apply the duplicate checking to some of the rows
- Keep the first row of a set of duplicates
- Support large XML values
- Develop this solution ASAP (this was needed in a critical support situation)
A single application had populated the table, so fortunately I could assume all XML was equally processed.
My Solution
Now in the heat of the moment I went with a hashed solution as StackOverflow proposed. Upon reflection however I don’t see a real reason (beyond perhaps performance) I couldn’t have followed Matt Woodward’s method and performed a simple string conversion and comparison (well a comparison of substrings given the requirement to ignore the header). Indeed it’s the improved solution I list below.
However, given the hashing direction the HASHBYTES function seemed a good start.
HASHBYTES (Transact-SQL)
Returns the MD2, MD4, MD5, SHA, SHA1, or SHA2 hash of its input.
Unfortunately, while this is a decent enough function for hashing, it led me on a bit of a wild goose chase as I tried to work out why I couldn’t seem to cast my XML field to varchar without getting an error. It turned out that this was because I was passing my cast value straight to HASHBYTES which was in turn throwing an error.
See much like a past post I had missed something pretty crucial on the MSDN page – HASHBYTES has an 8000 character limit!
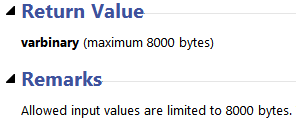
At least this time the implications were glaringly obvious, and I had noone else to blame but myself. In the process at least I learned a bit more about XML support in SQL, and found some pretty cool resources including this series of SQL XML Workshops from Jacob Sebastian found while searching on StackOverflow.
It turned out that conversion to XML was as easy as I’d first tried:
CONVERT(varchar(max), XmlColumn)
Once I got past this problem the query I ran with was pretty easy to put together.
First, I would only hash content from after the header, which I could identify by the character index of either the header closing tag or content start tag (found using CHARINDEX). I could have also used SQL Server’s XML query functions, but I was short on time and this seemed suitable for a throwaway task.
CHARINDEX('<Content>', CONVERT(varchar(max), XmlColumn))
Then I could use a SUBSTRING to grab the next 8000 characters (to support HASHBYTES) from this point:
SUBSTRING(
CONVERT(varchar(max), XmlColumn), --// Data
CHARINDEX('<Content>', CONVERT(varchar(max), XmlColumn)), --// Start Index
8000) --// Length
This ultimately gave me the following query, which suited our purposes:
--// WARNING: THIS CODE HAS A MAJOR ISSUE (SEE BELOW)
UPDATE OurTable
SET IsDuplicate = 1
WHERE
OtherFilters = 'SomeValue' --// Other filters, so only checking certain rows
AND Id NOT IN ( --// ID is either unique or matches the first 'duplicate'
SELECT MIN(Id) FROM OurTable --// Pick the lowest ID for a given hash
WHERE OtherFilters = 'SomeValue' --// Same as the OtherFilters above!
GROUP BY --// Group by hash (i.e. duplicates grouped)
HASHBYTES('md5', --// Hash Function
SUBSTRING( --// Hash Data (the substring of 8000 chars after the header)
CONVERT(varchar(max), XmlColumn), --// Substring Data
CHARINDEX('<Content>', CONVERT(varchar(max), XmlColumn)), --// Index
8000))) --// Length
Review
There is a major issue with this query! Can you spot it?
The problem is that it assumes the first 8000 characters of the XML (well, after the trimmed header) are enough for unique identification. While this may be a valid assumption (as it was in my case), if it’s wrong you run the risk of falsely labeling some XML a duplicate, which could be disastrous.
At the time I considered resolving this by appending the hashes of the next 8000 characters, possibly repeating if necessary to increase the character coverage (one of my less bright ideas).
In retrospect simple string comparison was not only sufficient, but a better (if not as performant) solution (the goose chase of believing that conversion of large XML to varchar had issues put this idea out of my mind). It also has the added benefit of avoiding admittedly unlikely MD5 collisions.
However, if performance is a concern (or depending on the number of rows and size of XML values involved) hashing may still be a good fallback option (perhaps even with my terrible ‘concatenated hashes’ approach). Alternatively I would probably look to point LINQPad at the database and write some pretty basic code to perform duplicate detection (which would have additional advantages if the XML was processed in different ways with regard to whitespace and self-closing tags).
Improved Solution
Assuming performance isn’t a serious bottleneck, something like the following works (and is what I’ve used subsequently):
UPDATE OurTable
SET IsDuplicate = 1
WHERE
OtherFilters = 'SomeValue' --// Other filters, so only checking certain rows
AND Id NOT IN ( --// ID is either unique or matches the first 'duplicate'
SELECT MIN(Id) FROM OurTable --// Pick the lowest ID for a given hash
WHERE OtherFilters = 'SomeValue' --// Same as the OtherFilters above!
GROUP BY --// Group by content (i.e. duplicates grouped)
SUBSTRING(
CONVERT(varchar(max), XmlColumn), --// Substring Data
CHARINDEX('<Content>', CONVERT(varchar(max), XmlColumn)), --// Start Index
LEN(CONVERT(varchar(max), XmlColumn)))) --// Length, excess is handled
Since originally publishing this I did a little more research on the issues with hashing, and should you go down this direction there’s a great article by Thomas Kejser on SQL hash functions and performance. For one, it makes sense to use something like SHA1 instead of the MD5 in my example as it reduces the likelihood of collision issues without a noticeable performance difference.
I have the feeling there’s much room for others optimisations and approaches here, so if anyone has run into this problem before or has some ideas on what to do next time I’m curious to hear more!
